
Data mining-based optimal assignment of apparel size for mass customization
DOI:
https://doi.org/10.25367/cdatp.2020.1.p20-29Keywords:
garment size, mass customization, data mining, clustering algorithm, K-means clustering, support vector machineAbstract
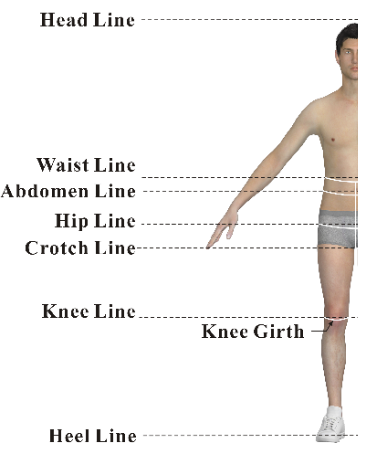
In this study, we have explored and discussed the data mining-based solutions to apparel size assignment using approach principle, K-means clustering, and support vector machine, respectively. A case of mass customization for men's pants in China with 200 adult males were employed to validate and evaluate the solutions. After anthropometric data acquisition and preprocessing, three key body dimensions were identified based on hierarchical clustering, as well as their ranges and fit models. Sequentially, we calculated all the possible values of the distance between the target population and the fit models by the enumeration algorithm. Afterward, we assigned the garment sizes for the target population using the abovementioned data mining approaches. Lastly, the solution based on support machine was considered as the optimal solution for pants mass customization after being comprehensively assessed by the aggregate loss of fit, the number of poor fit, accommodation rate of ideal fit, and the number of garment size employed, since it employed only 48 sizes to reach the accommodation rate of the target population up to 82%. The experimental results demonstrate that the present solution is a low-cost method for size assignment by exploiting the potentials of the existing sizing system, instead of creating new sizing systems, and also easy to be flexibly extended to any types of garments.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2020 Zhujun Wang, Cheng Chi, Mengyun Zhang, Xianyi Zeng, Pascal Bruniaux, Jianping Wang, Yingmei Xing

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.




